Student Projects
VE/VM450
Real-time Road Condition Analysis Based on Point Cloud and Depth Image
Sponsor: Bin Ge, HASCO VISION
Team Members: Pengyi Cao, Chongyu He, Yueyuan Li, Zhizheng Liu, Junjie Luo
Instructor: Prof. Jigang Wu
Project Video
Team Members

Team Members:
Pengyi Cao
Chongyu He
Yueyuan Li
Zhizheng Liu
Junjie Luo
Instructor:
Prof. Jigang Wu
Project Description
Problem Statement
Autonomous driving is a foreseeable trend in the future. One of its greatest challenges is the detection of the surrounding environment. This project aims to build a model to help analyze the complex road conditions based on LiDAR point cloud(Fig. 1) and depth images(Fig. 2). By detecting surrounding roads, cars pedestrians and cyclists, we can lower the risk of an accident.

Fig. 1 Point cloud data with the colors representing different depths
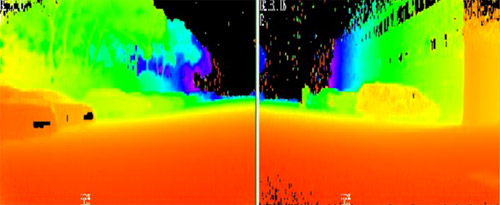
Fig. 2 Depth image
Concept Generation
Our system is divided into two parts: object detection and road detection. Results of these two sub-systems are then combined together to form a complete road condition analysis. Based on VoxelNet, the object detection sub-system learns features directly from point cloud, while the road detection sub-system based on SalsaNet learns features from bird-eye-view images projected from raw point cloud.
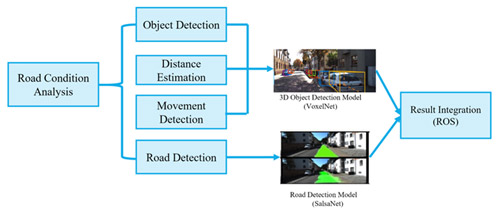
Fig. 3 Concept Diagram
Design Description
The sub-system of object detection has three major steps.
Feature extraction: It first partitions the LiDAR point into voxels based on their position and then it performs a random sampling for each voxel.
Convolutional middle layers: Extracted features are processed to aggregate spatial context
Region proposal network: The RPN consumes the volumetric representation and obtains the detection result.
The sub-system of road detection first projects LiDAR point cloud into a 256×64×4 bird eye view projection, and processes it with an encoder-decoder structure.
Encoder: This part contains a series of five ResNet blocks. These blocks reformulate the layers as learning residual functions with reference to the layer inputs. Each block, except the last one, is followed by dropout and max-pooling layers.
Decoder: It includes four de-convolutional layers to up sample feature maps. Finally, a soft-max classifier obtains pixel-wise classification from the resulting feature map.
Modeling and Analysis
The model built for road condition analysis is developed on Python. Frames of LiDAR point cloud and depth image are read by the program, and the output is labelled LiDAR point cloud. Fig 4 shows the result.
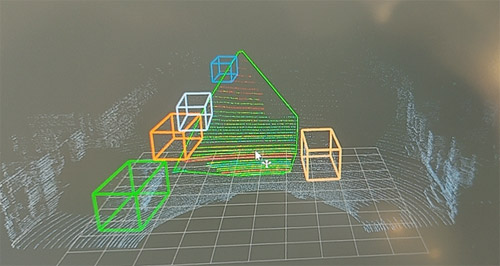
Fig. 4 Detection Result
Validation
Validation Process:
For the accuracy of object detection and road detection, we utilized official evaluation toolkit provided by KITTI dataset[1], which is a website of lots of authoritative and integrated test suits for 3D object detection and 3D tracking.
For the runtime, we employ a timer to record the runtime while running tests provided by KITTI dataset. Dividing the overall runtime by number of images gives the average processing speed in ms per image.
Validation Results:
According to validation part, most specifications can be met.
√ AP for object detection >= 85%
√ Runtime <= 70ms per image
√ image size = 512×64×5
√ Cost <= 3000RMB
• AP for road detection >= 85%
√ means having been verified and · means to be determined.
Conclusion
Our road analysis system is designed to provide real-time road detection, object detection and classification for autonomous vehicles, which will have positive effects in improving driving safety and solving urban traffic congestion problems. The novelty of our project can be reflected by the fusion of LIDAR point cloud and depth map, and the combination of multiple tasks in a single system.
Acknowledgement
Sponsor: Bin Ge, HASCO VISION
Main Li, Chengbin Ma, Chong Han, Jigang Wu, Shouhang Bo from UM-SJTU Joint Institute
Tao Lu, Xiang Hao, Yibo Chen, Zhikang Li, Allen Zhu from UM-SJTU Joint Institute
Reference
[1] KITTI Dataset Access Date: Jul 20, 2020 http://www.cvlibs.net/datasets/kitti/